This is a brief post on collecting and analysing tweets. I will show how to use the rtweet package to extract Twitter posts about the R community. This ties into last weeks post on rstudio::conf and community values, and is also related to my previous intro post on web scraping.
First, we load rtweet and other (tidyverse) packages we will need:
libs <- c('dplyr', 'tibble', # wrangling
'stringr', 'rtweet', # strings, tweets
'knitr', 'kableExtra', # table styling
'lubridate', # time
'ggplot2', 'ggthemes') # plots
invisible(lapply(libs, library, character.only = TRUE))In order to use the rtweet package you need a Twitter account and the package needs to be authorised to access that account. The authorisation process is very smooth: just run a command like the one below and an authorisation tab will open in your browser (via rstats2twitter). Approving the authorisation will store a credential token on your machine (called .rtweet_token.rds) for a all future requests. This token should end up safe in your home directory, but you might still want to double check that it doesn’t get pushed to any public github repos.
This is how we search for recent tweets about “rstats” + “community”:
rt <- search_tweets(
"rstats community", n = 1000, include_rts = FALSE
)In the search string, white space acts like “AND” and order doesn’t matter. To search for either term (inclusive) you can use “OR”. To search for specific sequences of terms wrap them in single quotes (e.g. ‘rstats community’). The search_tweets help page has further and more detailed query instructions.
Note: the free Twitter API only allows you to access tweets from the last 6-9 days. For anything more you need a paid API. I was originally planning to search for #rstudioconf tweets, but the conference is 3 weeks ago now. So I guess that’s what I get for taking so long with this post.
Twitter’s request limit is 18k tweets per 15 minute interval. To download more tweets in one go you can set the parameter retryonratelimit = TRUE, but you would have to wait 15 min for the retry. This is a convenience function, so that you don’t need to run individual 18k queries and stack them together by yourself.
With search_tweets we can derive pretty much all the information about a tweet, its author, and any quoted tweets: the full text, retweet count, hashtags, mentions, author bio; you name it. A total of 90 columns. Not all of them will always have values, but it looks like a very comprehensive set of features to me. Here is a small subset of those features: the date-time of the tweet (in UT), the user name, and the number of followers:
rt %>%
select(tweeted = created_at,
screen_name,
followers = followers_count) %>%
head(5) %>%
kable() %>%
column_spec(1:3, width = c("45%", "35%", "20%")) %>%
kable_styling()| tweeted | screen_name | followers |
|---|---|---|
| 2020-02-20 18:32:47 | danicassol | 157 |
| 2020-02-20 17:51:03 | LK_Fitzpatrick | 511 |
| 2020-02-20 17:40:19 | PyData | 48209 |
| 2020-02-20 16:34:52 | rOpenSci | 28207 |
| 2020-02-20 13:24:03 | GiusCalamita | 38 |
We’ll conclude with some (small number) statistics about “rstats” “community” posts. The rtweet docs include many more examples and inspiration for projects. This is the frequency of tweets over the last week:
rt %>%
mutate(date = date(created_at)) %>%
count(date) %>%
ggplot(aes(date, n)) +
geom_line(col = "blue") +
labs(x = "", y = "") +
theme_fivethirtyeight() +
theme(legend.position = "none") +
ggtitle("Daily number of tweets about the 'rstats community'",
subtitle = "Extracted using the rtweet package")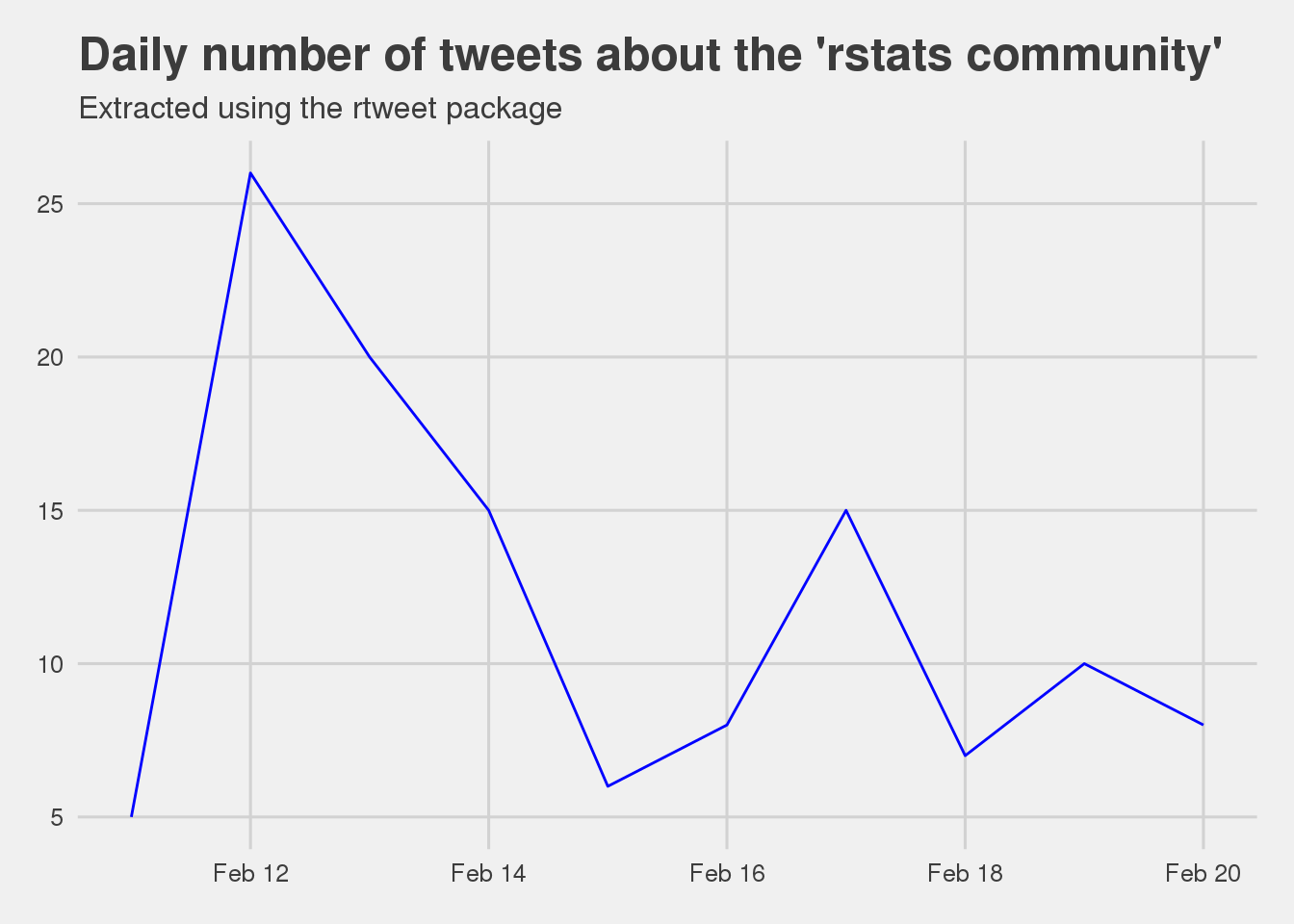
The notable spike on Feb 12 was caused by @kierisi asking about people’s experiences with the community. I’m looking forward to her blog post:
I'm working on a presentation about the R Community (yes, yes I'll make a blog post!) and while I have *my* opinions, I'd really love to showcase your experiences!
— Jesse Mostipak 🦦 (@kierisi) February 12, 2020
What motivated you to join the #rstats community? Why do you participate? What makes you stay?
(DMs are OK, too!) pic.twitter.com/7h3xKZ0Cg2