In my final post on setting up yearly goals I will write about how to track progress and finally add some data visuals. Building your own progress dashboards adds a nice meta level of data science to the journey and gives you more control over how to track your goals.
We’re loading the popular libraries for data wrangling and visuals:
libs <- c('dplyr', 'stringr', 'forcats', # wrangling
'tidyr', 'readr', # wrangling & reading
'gt', # table styling
'lubridate', # date & time
'ggplot2', 'ggthemes', # plots
'ggridges', 'patchwork') # plots
invisible(lapply(libs, library, character.only = TRUE))Track or be tracked
When it comes to tracking methods, I’m using multiple apps and tools:
For general time tracking, I like to use aTimeLogger. It’s easy to use and to customise, and it allows you to export your data as csv files. (Which is by no means a given for apps like this.)
My workout data I’m tracking in an app called FitNotes, which is a general fitness log tool. Also here you have a lot of control over how to set up your exercises; and you can export your data easily.
When it comes to running, I’m using a Garmin Forerunner 35 watch from the lower end of their range. It has good battery and decent GPS, which is really all I need to track my kilometers.
I had the watch for a good 2 years now and its robust and reliable. There is an app and dashboard tool called Garmin Connect associated with it, which gives you a decent overview of your status and achievements. However, I haven’t found a good way yet to extract this data in a way that I can analyse it. For now, I’m just copying my overall running stats (time & distance) into FitNotes and include them into that csv file. But I’m hoping that there’s a good way to get more decent stats from Garmin directly. If you happen to know more about this, please let me know.
When it comes to the apps, FitNotes and aTimeLogger, I’ve been using them for years in various ways. In the old days, I still used a paper notebook for my gym and running workouts. And already that made a major difference by giving me a baseline to try to improve on in the next workout. Nowadays apps make this process quite a bit easier, as long as you don’t allow your phone to distract you during sets.
The time logging I started to use to get better control of my habits and time management. Anyone who has ever sat down in front of their laptop to “quickly check out this new Kaggle competition”, only to look up 5 hours later and wonder why you’re getting hungry, will understand what I mean. There are different levels of strictness with which one can approach this time tracking thing; and as so often in life it’s best not to get too carried away with it. It’s hardly useful to track every single thing, or to fret about minutes. I’m using it to track my sleep, as well as my time on Kaggle and (in 2022) the time I spend learning ML techniques.
The data
I’m sharing some of my personal data here, but mostly on a high, aggregated level except for the run data which is already pretty granular in the visuals I’m using. Always good to be at least aware of how much of your data you’re giving to the world. I’ve been tweeting quite a bit about my running progress, so there’s nothing really new here. The sleep visuals will be more aggregated.
As an example, the running data looks like this:
run %>%
tail(20) %>%
gt() %>%
tab_header(
title = md("**Last 20 runs in 2021**")) %>%
cols_label(
date = "Date",
dist = "Distance (km)",
dur = "Duration",
pace = "Pace (min/km)"
) %>%
opt_row_striping() %>%
tab_options(container.height = px(400))| Last 20 runs in 2021 | |||
|---|---|---|---|
| Date | Distance (km) | Duration | Pace (min/km) |
| 2021-10-26 | 5.00 | 27M 13S | 5.443333 |
| 2021-10-28 | 4.56 | 21M 12S | 4.649123 |
| 2021-11-02 | 10.00 | 52M 41S | 5.268333 |
| 2021-11-04 | 5.00 | 22M 50S | 4.566667 |
| 2021-11-06 | 34.00 | 3H 20M 58S | 5.910784 |
| 2021-11-10 | 5.00 | 26M 27S | 5.290000 |
| 2021-11-17 | 5.00 | 31M 37S | 6.323333 |
| 2021-11-21 | 10.74 | 1H 0M 0S | 5.586592 |
| 2021-11-23 | 10.00 | 54M 25S | 5.441667 |
| 2021-11-25 | 5.00 | 24M 53S | 4.976667 |
| 2021-11-28 | 21.16 | 2H 0M 0S | 5.671078 |
| 2021-12-01 | 5.00 | 24M 3S | 4.810000 |
| 2021-12-03 | 10.71 | 1H 0M 0S | 5.602241 |
| 2021-12-05 | 42.20 | 4H 24M 52S | 6.276461 |
| 2021-12-09 | 10.00 | 57M 45S | 5.775000 |
| 2021-12-12 | 17.45 | 1H 30M 0S | 5.157593 |
| 2021-12-16 | 5.00 | 28M 19S | 5.663333 |
| 2021-12-21 | 5.69 | 30M 0S | 5.272408 |
| 2021-12-23 | 16.11 | 1H 30M 0S | 5.586592 |
| 2021-12-28 | 5.00 | 25M 55S | 5.183333 |
Here I’m using the fantastic gt package, which likely deserves its own blog post in the future. For now, this table should demonstrate that for each run I’m collecting the date, distance, duration, and pace (which is derived from duration / distance). Those last 20 runs of 2021 include my successful marathon distance of which I’m disproportionately proud.
Running Visuals
Let’s stay with the topic of running and continue with the visuals. One of the overview plots I had chosen for tracking the time and distance that I spent running each month.
run %>%
mutate(dur = as.numeric(dur)/3600) %>%
mutate(month = lubridate::month(date, abbr = TRUE, label = TRUE)) %>%
group_by(month) %>%
summarise(dist = sum(dist),
dur = sum(dur)) %>%
pivot_longer(c(dist, dur), names_to = "type", values_to = "val") %>%
mutate(type = if_else(type == "dist", "Distance Run (km)", "Run Duration (h)")) %>%
ggplot(aes(month, val, fill = type)) +
geom_col() +
scale_fill_viridis_d() +
facet_wrap(~ type, ncol = 1, scales = "free_y") +
theme_hc() +
theme(legend.position = "none") +
labs(x = "", y = "", title = "Total Time and Distance run per Month")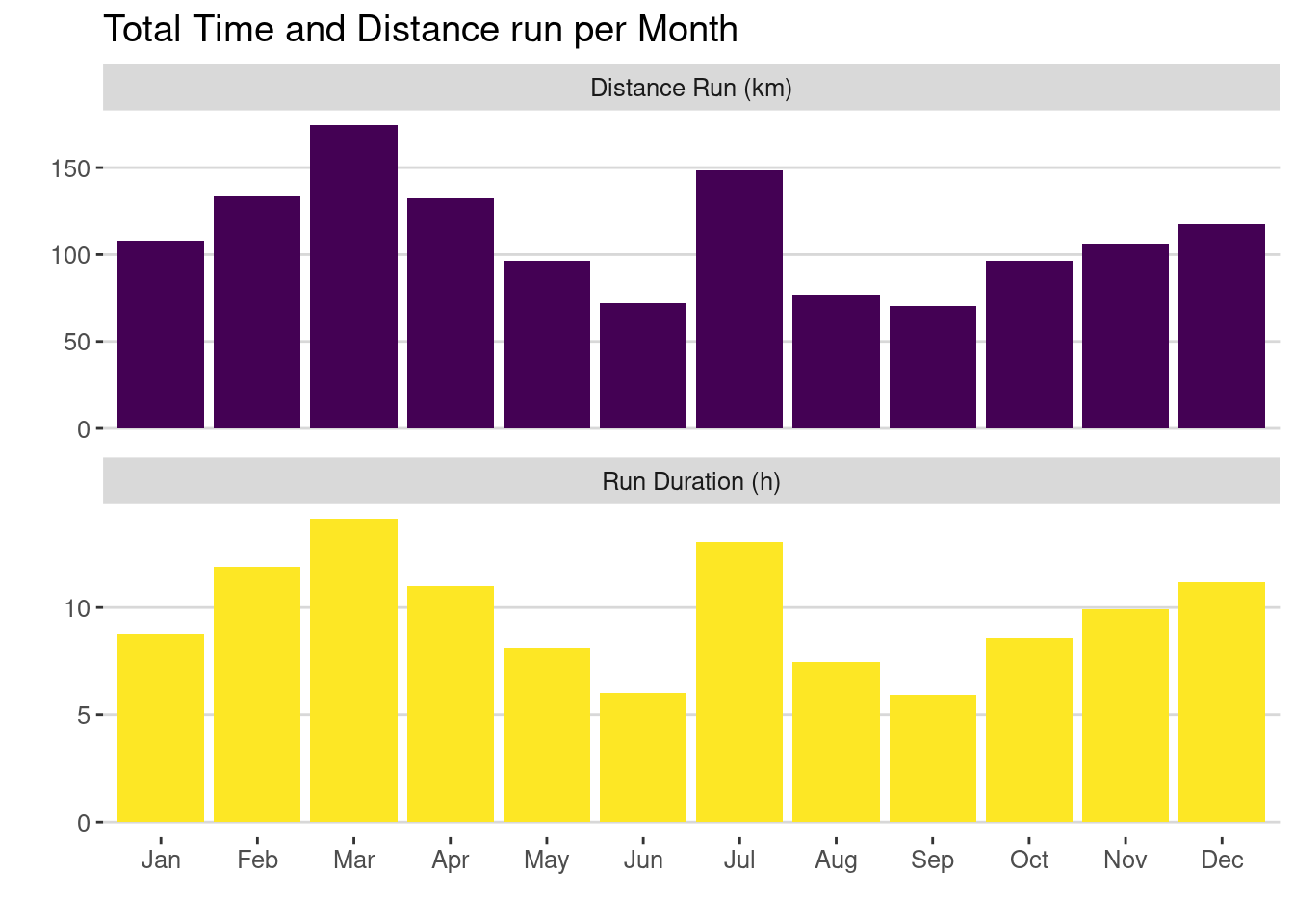
You’ll see that I was ramping up my kilometers in pursuit of the marathon first in March and then again in July, but both times travel and Covid vaccines intervened before I could reach my goal. Finally, a slightly more gradual increase in monthly distance proved successful in December. This kind of high level plot can put each month into perspective, and show the bigger picture of your progress. It is simple yet effective, and you could aim to gradually increase the size of the monthly bar leading up to your goal.
Another overview visual I made was more detailed: it shows the evolution of each individual run distance over time. Overlayed are horizontal bars at the 5k, 10k, half marathon, 30k, and marathon marks. There are no runs shorter than 5k here:
marathon <- 42.195
run %>%
ggplot(aes(date, dist)) +
geom_line() +
geom_point() +
#geom_smooth(data = run %>% filter(dist >= 10), method = "loess", formula = "y ~ x", se = FALSE, span = 1) +
geom_hline(yintercept = c(5, 10, marathon/2, 30, marathon),
color = c("#5fcea8", "#1fccff", "#956296", "#e56c3a", "#e8bb34")) +
theme_minimal() +
labs(x = "", y = "", title = "Path to Marathon: Run Distance over Time")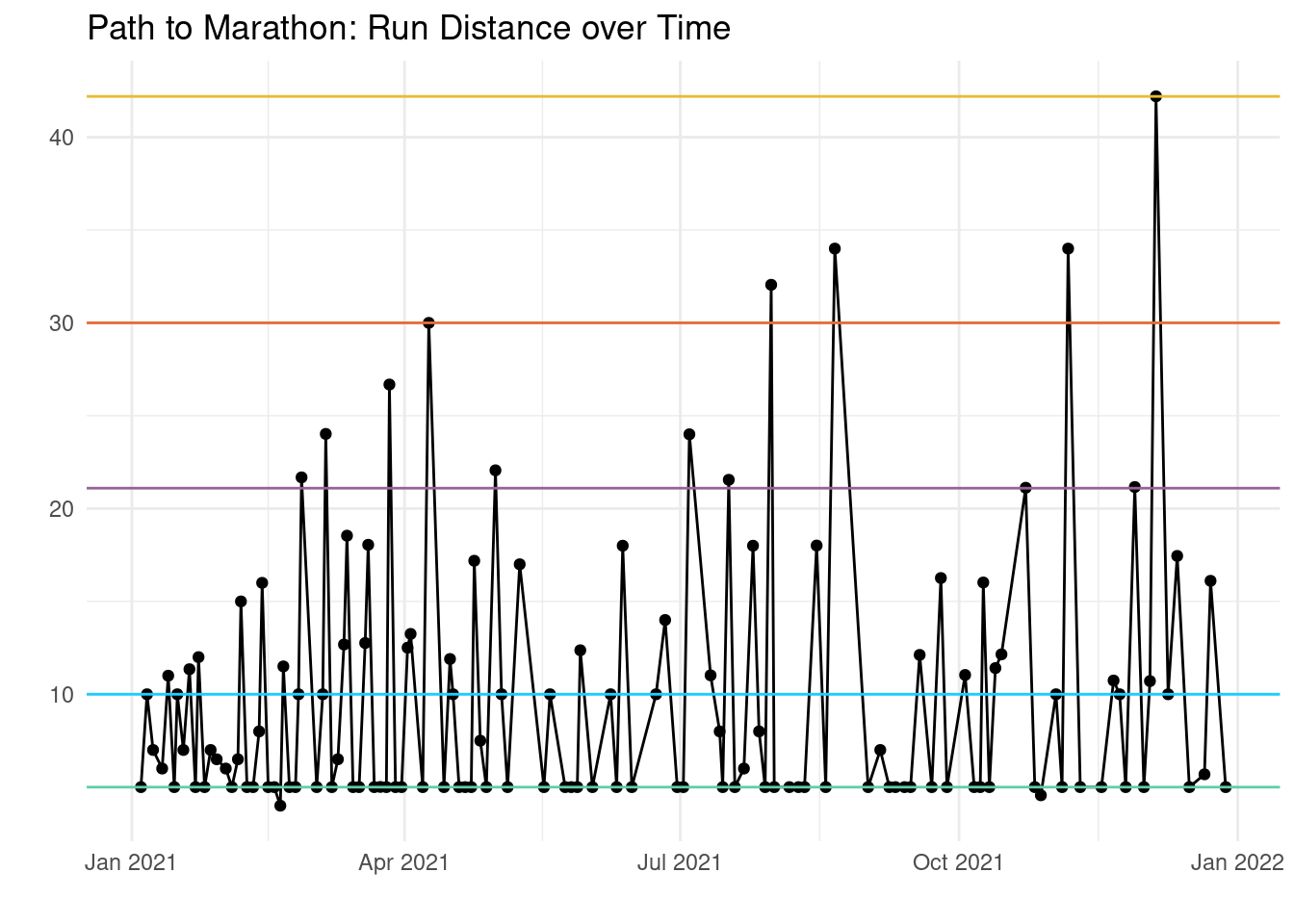
If you’re a Kaggler, you might recognise that I’ve chosen the colours of those milestones according to the Kaggle progression system, with the marathon being Grandmaster tier. Gotta learn from the best when it comes to gamification ;-)
Depending on your number of workouts, such a plot can get messy. But it’s not so much about the individual runs, but rather the emerging patterns. From Jan to Apr you see me aiming for gradually longer runs, with the occasional week of short runs thrown in between. My eventual progress towards the successful marathon attempt in December was faster in comparison. But you also see the consistent trend throughout the year that was leading up to it (with an intermittent spike in Jul/Aug). Without this birds eye view, a period of shorter runs could easily be mistaken for failure
Progress is rarely linear. Especially when it comes to physical goals, you shouldn’t expect to just increase your results every week without fail. As a layperson, I understand that there is a cyclical pattern to physiological processes: you work out and it taxes your body; your body then recovers and even increases its strength during rest. Rest is just as important as exercise. It will be to your advantage to listen to your body and to track and recognise those cyclical patterns in your workout progression.
Sleep Visuals
My sleep goal was conceptually different from my running goal, and thus I chose a different visualisation style. I was aiming to stay above 8 hours of sleep per night throughout the year, and I tracked this on a monthly level.
A barplot, like above, would do a fine job in keeping track of the average monthly sleep time. But I was also interested in the variance in those numbers. Sleep duration is a continuous variable, for which my preference is to start with density plots. A sequence of (monthly) density plots can nicely be constructed using the great ggridges package. In addition, I’m plotting alongside the mean and standard deviations of those distributions using horizontal error bars. The side-by-side composition of those two plots is provided by the fantastic patchwork package:
p1 <- sleep %>%
ggplot(aes(dur_day, month, fill = month)) +
geom_density_ridges(bandwidth = 0.3) +
scale_fill_viridis_d() +
theme_minimal() +
theme(legend.position = "none") +
labs(x = "Hours", y = "", title = "Hours of sleep per day for months")
p2 <- sleep %>%
group_by(month) %>%
summarise(mean = mean(dur_day),
sd = sd(dur_day),
sum = sum(dur_day)) %>%
# pivot_longer(c(mean, sum), names_to = "type", values_to = "val") %>%
ggplot(aes(month, mean, col = month)) +
geom_point(size = 4) +
geom_errorbar(aes(ymin = mean-sd, ymax = mean+sd), size = 1) +
coord_flip() +
# scale_y_continuous(breaks = c(6, 7, 8, 9))
# facet_wrap(~ type, scales = "free_x") +
theme_minimal() +
theme(legend.position = "none") +
labs(x = "", y = "Hours", title = "Average hours per day")
p1 + p2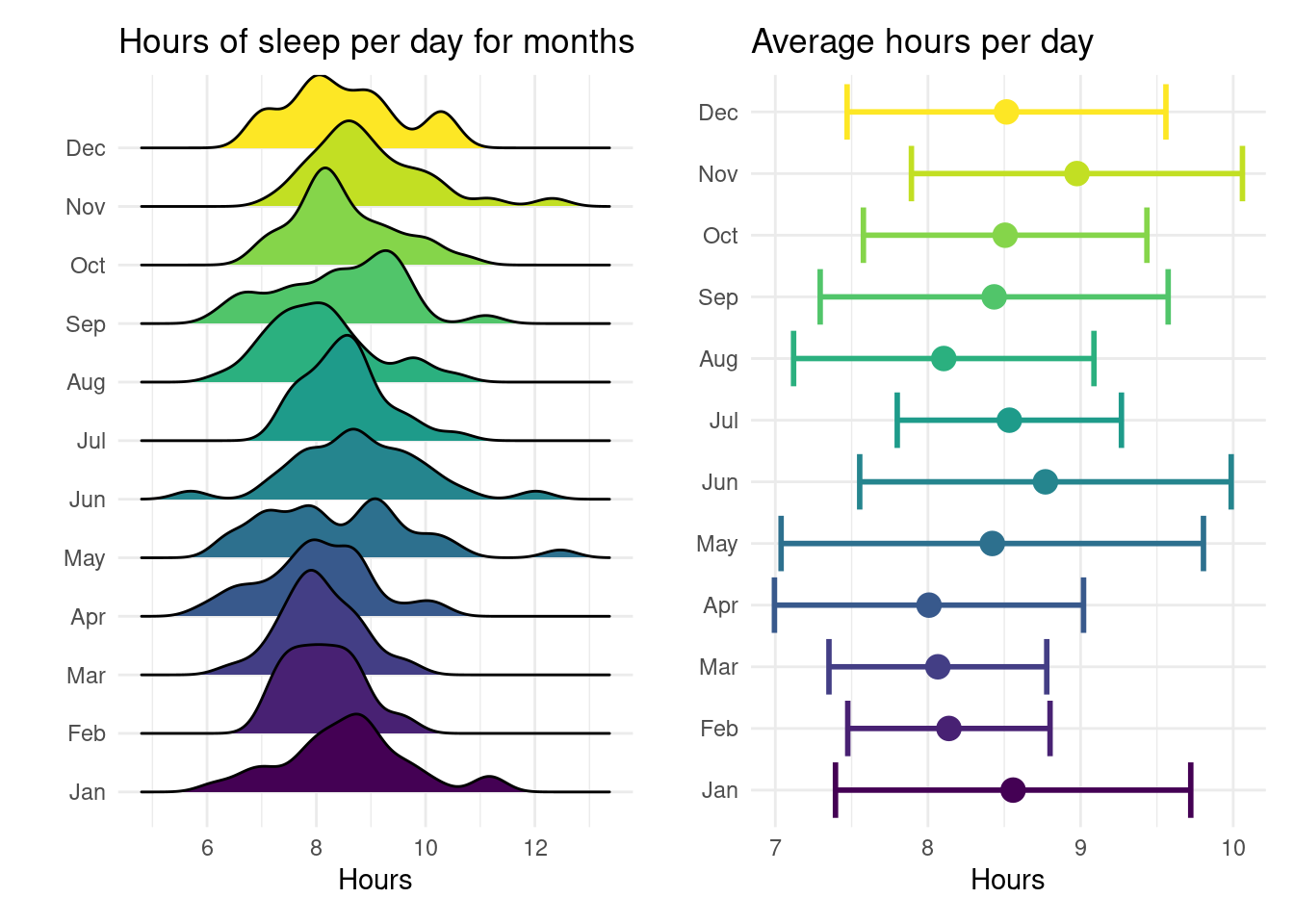
You can clearly see the broad and rather misshapen distributions, as well as the fact that their centers were shifting quite a bit over time. While the error bars give an immediate indication of the narrowness of the distribution, the density plots show skewness, multiple peaks, and outlier values. Although I succeeded in my sleep goal overall, there are more of those outliers than I would have liked. This is something I intend to improve on this year.
Progress bars
Last but not least, I’d like to present an argument in favour of the humble progress bar. Bars that continously update as the year is progressing can be a great method for tracking and motivation. I’m using two slightly different bars here for sleep and running.
The running bar in grey is set at the distance of the marathon goal. The green bar then fills in more and more of this bar as I’m pushing my maximum run distance further and further. Eventually, the green bar will fully cover the grey background.
The sleep bar is tracking the total hours of sleep throughout the year. The vertical overlayed on it does at the same time progress at the speed of 8 hours per day. You want to try to keep the bar ahead of the line at all time.
goal_sleep <- 8
goal_run <- marathon
p1 <- run %>%
filter(dist < max(dist)) %>%
summarise(dist = max(dist)) %>%
mutate(type = "Run") %>%
ggplot(aes(type, dist)) +
geom_col(aes("Run", goal_run), fill = "grey70") +
geom_col(fill = "darkgreen") +
coord_flip() +
theme_minimal() +
theme(axis.text.y = element_blank(), axis.ticks.y = element_blank()) +
labs(x = "", y = "Longest Run in km", title = "Maximum Run Distance before marathon")
p2 <- sleep %>%
summarise(dur = sum(dur_day)) %>%
mutate(type = "Sleep") %>%
ggplot(aes(type, dur)) +
geom_col(aes("Sleep", goal_sleep * 365), fill = "grey70") +
geom_col(fill = "darkblue") +
geom_hline(yintercept = 365 * goal_sleep, linetype = 2) +
coord_flip() +
theme_minimal() +
theme(axis.text.y = element_blank(), axis.ticks.y = element_blank()) +
labs(x = "", y = "Hours of Sleep", title = "Total Sleep in 2021 with moving goal")
p1 / p2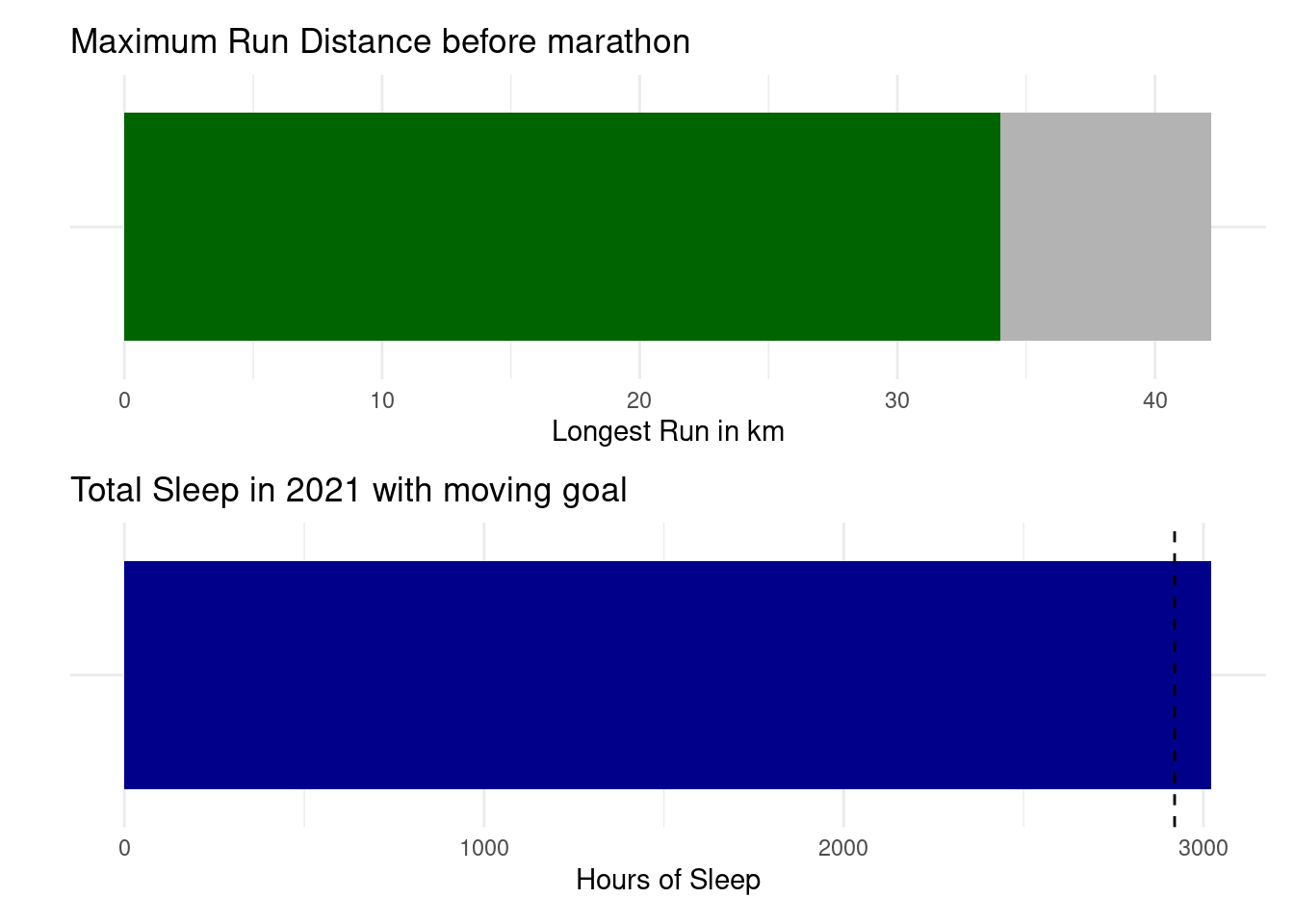
To display all those individual visuals together nicely, I’m making use of the flexdashboard package which can easily turn an Rmarkdown script (such as this blog post) into a static dashboard.
There are many more ways of building tracking visuals, but for now this is the end of this post. We will revisit some of those plots in an update post on the progress towards my 2022 goals, about halfway through the year. Until then, best of success with your goals for 2022!