I have long been a fan of creative data visualisation techniques. For me, the choice of visual representation is driven by both the type of data and the kind of question one wants to examine.
The power of its visualisation tools has been a major strength of the R language well before the ggplot2 package and the tidyverse burst onto the scene. Today’s post will be an introductory examination of two similar packages that allow us to study the connection and flow of data between different categorical features via alluvial plots. Those packages are alluvial and ggalluvial.
All in all we need the following libraries:
libs <- c('dplyr', 'stringr', 'forcats', # wrangling
'knitr','kableExtra', # table styling
'ggplot2','alluvial','ggalluvial', # plots
'nycflights13') # data
invisible(lapply(libs, library, character.only = TRUE))Alluvial plots are best explained by showing one. For illustrating the following examples we will take on board the flights data from the nycflights13 library. This comprehensive data set contains all flights that departed from the New York City airports JFK, LGA, and EWR in 2013. For this analysis, we will only look at three features - the 1st-class features if you will: airport of origin, destination airport, and carrier (i.e. airline code). From the metaphorical front of the cabin, here are the first 4 rows:
| origin | carrier | dest |
|---|---|---|
| EWR | UA | IAH |
| LGA | UA | IAH |
| JFK | AA | MIA |
| JFK | B6 | BQN |
The alluvial package was introduced in 2014 to fill a niché in the landscape of visualisations. I have enjoyed using it in the past in several Kaggle Kernels. Here’s what a plot looks like:
top_dest <- flights %>%
count(dest) %>%
top_n(5, n) %>%
pull(dest)
top_carrier <- flights %>%
filter(dest %in% top_dest) %>%
count(carrier) %>%
top_n(4, n) %>%
pull(carrier)
fly <- flights %>%
filter(dest %in% top_dest & carrier %in% top_carrier) %>%
count(origin, carrier, dest) %>%
mutate(origin = fct_relevel(as.factor(origin), c("EWR", "LGA", "JFK")))
alluvial(fly %>% select(-n),
freq=fly$n, border=NA, alpha = 0.5,
col=case_when(fly$origin == "JFK" ~ "red",
fly$origin == "EWR" ~ "blue",
TRUE ~ "orange"),
cex=0.75,
axis_labels = c("Origin", "Carrier", "Destination"),
hide = fly$n < 150)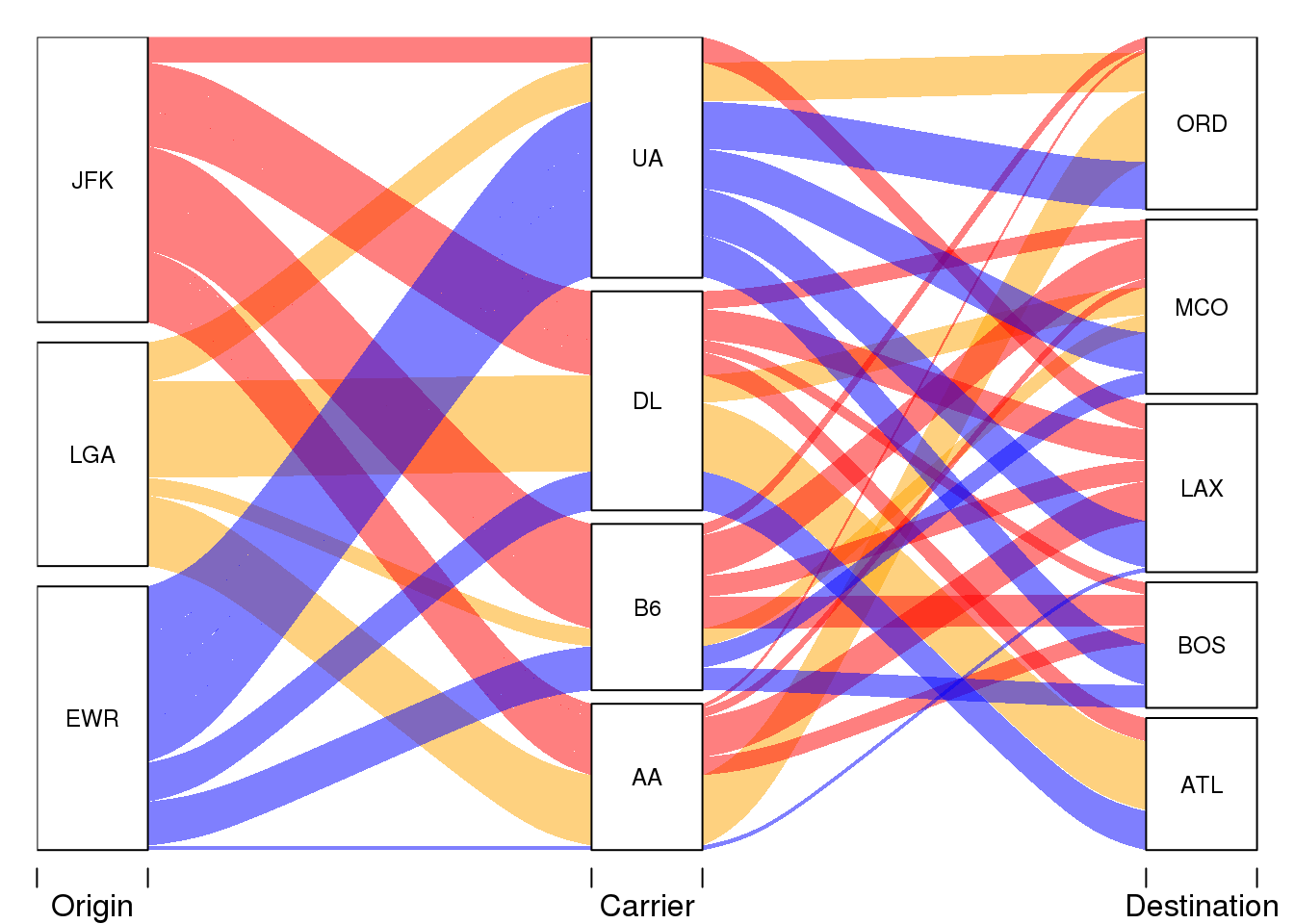
The features are arranged horizontally, with their value counts stacked vertically. This corresponds to a stacked barplot: e.g. for the destinations “BOS” has fewer flights than “LAX”. Here we only look at the top 5 destination and their top 4 carriers (that’s the first two segments of the code above).
The “alluvia” are the bands that connect the features from left to right. Alluvia break down all feature combinations, with complexity increasing also from left to right. These sub-segments are called “flows”.
This means that starting from the 3 origin airports on the left there are 4 “flows” each (i.e. 12 in total) connecting to the 4 main carriers. Between carrier and destination these then fan out into 5 flows each for a theoretical total of 60 different flows. In practice, we want to use the
hideparameter to exclude those flows that only have a few observations so that we can focus on the big picture.For further styling, a
bordercolour can be assigned to each alluvium. This would allow us to distinguish the different flows on the left side that then break into sub-flows on the right side. Feel free to try it out. Personally, I think the plot looks better without border colours.We chose a colour coding (argument
col) that puts focus on the origin airports. The first argument of thealluvialfunction is the data set, followed by the frequency column (freq). Note thatalluvialexpects the data already to be in the shape of grouped counts (as prepared viacountin the third code segment above).In my view, the best transparency for alluvia is the default
alpha = 0.5. As usual,cexdoes the font scaling andaxis_lablesis pretty self-explanatory.The
alluvialfunction has anorderingparameter, but it’s generally better to do the ordering through factor re-levelling when preparing the data (via the tidyverse forcats library). Here we only change the order for theoriginfeature.
So, other than looking pretty, what insights does it give us? Well, for instance we see that (for this subset) EWR is dominated by UA (United Airlines) and has almost no AA (American Airlines flights). In turn, UA flights are not frequent in LGA or JFK. Both Boston (BOS) and Los Angeles (LAX) are not connected to LGA (orange). Thus, the alluvial plot shows us - pretty literally in this case - the flow of flight volume between airports through airline carriers.
Now, the alluvial tool has a rather specific syntax and doesn’t integrate seamlessly with the tidyverse. Enter the ggalluvial library:
fly %>%
mutate(origin = fct_rev(as.factor(origin)),
carrier = fct_rev(as.factor(carrier)),
dest = fct_rev(as.factor(dest))) %>%
filter(n > 150) %>%
ggplot(aes(y = n, axis1 = origin, axis2 = carrier, axis3 = dest)) +
geom_alluvium(aes(fill = origin), aes.bind=TRUE, width = 1/12) +
geom_stratum(width = 1/4, fill = "white", color = "black") +
geom_text(stat = "stratum", label.strata = TRUE) +
scale_x_discrete(limits = c("Origin", "Carrier", "Destination"),
expand = c(.05, .05)) +
scale_fill_manual(values = c("red", "orange", "blue")) +
labs(y = "Cases") +
theme_minimal() +
theme(legend.position = "none") +
ggtitle("NYC flights volume for top destinations and airlines")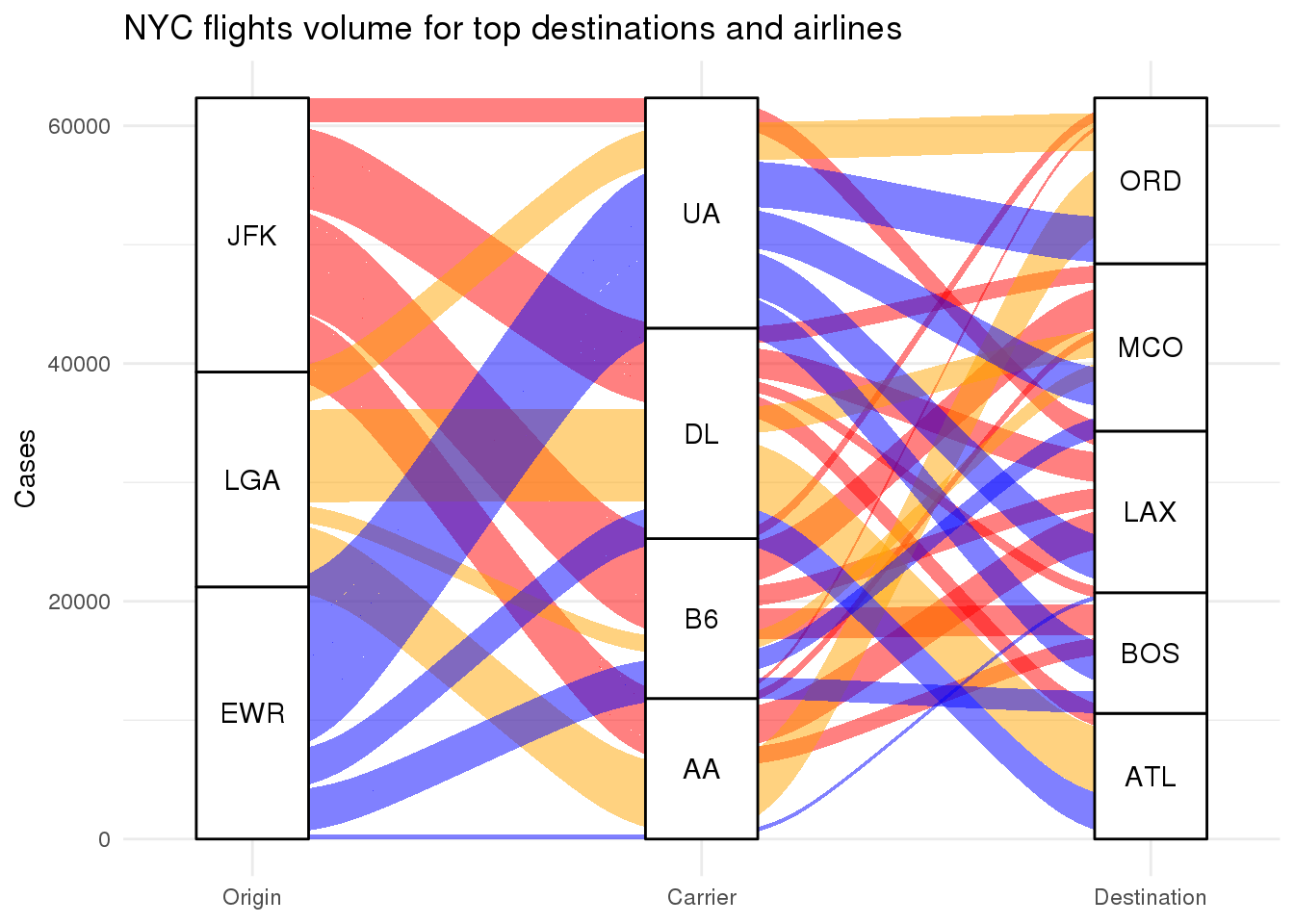
Here I purposefully choose the styling parameters to (broadly) reproduce the above plot. It is evident that ggalluvial integrates much more smoothly into the ggplot2 grammar. Specifically:
The alluvia and the vertical features (the “strata”; here: origin, carrier, and destination) are implemented as different geometry layers. Note, that the default order of the strata features is reversed compared to
alluvial. Also: there are no gaps between the strata here compared to whatalluvialdoes. This makes it easier to add a y-axis.I decided not to change the default y-axis and subtle background grid lines, which provide quantitative information and guide the eye. Replace
theme_minimal()bytheme_void()to get very close to thealluvialplot style.By default,
ggalluvialplots the same number of flows between neighbouring strata. This behaviour can be changed by theaes.bind=TRUEparameter ingeom_alluvial. Remove it to see the difference with a larger number of narrower flows between the origin and carrier strata.We are setting the colours manually. One advantage of
ggalluvialis that instead of a manual setting you can use anyggplot2(or add-on) scale such asbrewerorviridis. Similarly we can modify the plottheme.Instead of
geom_textyou can usegeom_label, e.g. in combination with a differentfillcolour ingeom_stratum.
In closing: both packages are versatile and provide somewhat different approaches to creating alluvial plots. If you are frequently working within the tidyverse then ggalluvial might be more intuitive for you. Specific (edge) cases might be better handled by one tool than the other.
For more information check out the respective vignettes for ggalluvial and alluvial as well as their pages on github.
Have fun!